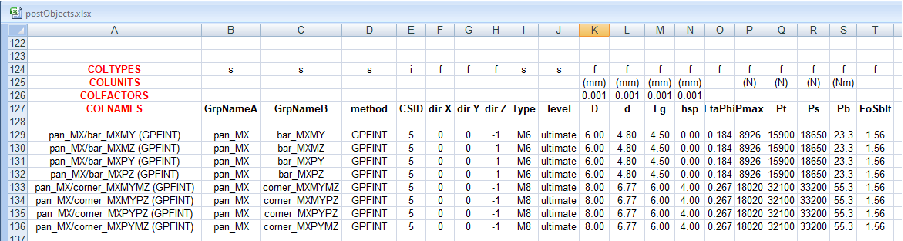
Figure IV.4.1: Example of definition of data in excel CSV file for the postprocessing of
interface data. The example corresponds to the definition of data for the calculation of bolts.
Most of the definition of data is done by functions defined in “PROJECT/DATA” sub-directory. The main data files are directly located in “PROJECT’ main directory however. The main data files are:
Data are interpreted by calling different ruby methods and build different kinds of objects:
In general, the post-processing object is instanciated and initialized according to values read from a CSV file. The CSV files are located in “PROJECT/DATA/CSV_POST” directory. In “PROJECT/static.rb” main source file, the post-processing objects are build by the following calls:
“Static” module also defines an iterator that is just a “wrapper” around another iterator defined in “DbAndLoadCases” module. This wrapper iterator looks as follows:
It is called from the main ruby file “PROJECT/static.rb” as follows:
(Note that we could have called “DbAndLoadCases.loopOnStaticCases()” iterator directly.)
In “PROJECT/static.rb” main source file, the building of the databases and load cases is done via the following line:
The details of the data are found in the CSV files.
(The trick is to provide the appropriate parameters to the
“DbAndLoadCases.loopOnDynamSubCases” iterator method.)
The idea of using CSV files to store the definition of parameters is a legacy from the excel post-processing described in Chapter VII.4. But it is also a very effective way to define the data. It improves the readability of data definition, and the combination of data definition in a combination of ruby code and CSV files ensures the flexibility needed to deal with specific cases.
Note that on of the post-processing data definition function does not involve the reading of a CSV file: “getSandwichData” method defines all the data in ruby code. This has been done because only one corresponding instance is created in the project. However, in more normal circumstances, it would be advantageous to define the data in a CSV file as well.
In general, the meaning of a parameter in a CSV filedepends on the index of the column in which it is defined. Then, it is the responsibility of user to verify that the in each CSV data line, each value is inserted in the appropriate column, so that ruby code that interprets CSV lines fills the appropriate parameters for the construction of each “post” object.
For the post-processing of connections, the CSV file “Interfaces.csv” that defines the data is formatted following conventions that differ from those adopted for the other types of post-processing criteria. Correspondingly the ruby method that reads the CSV lines and interprets them works differently. The CSV file is characterized by the insertion of directive lines that start with a keyword and specify how the following CSV lines must be interpreted:
An example of CSV lines with interpretation directives is presented in Figure IV.4.1. (Directive keywords are coloured in red in the excel worksheet.) We observe that the factor 0.001 is always associated to data specified in millimeters. This corresponds to the conversion of these values to meters.
The approach for connection “post” objects construction is more flexible. It allows to consider several formats for the different lines of a CSV file. This is particularly appropriate for the definition of connection “post” objects, because the post-processing failure criteria may differ significantly depending on the interface considered.